
Tout avait commencé en 1976. C’était longtemps avant Google et les GAFA. Je commençais à travailler sur ma thèse et il me fallait gagner ma vie. Je fus recruté par un cabinet d’études de marché, profession dont j’ignoraIs à peu près tout.
Le dirigeant de cette officine, Jean Michel Bourdier, s’était fait une spécialité d’analyser le discours des consommateurs en comptant les mots. Cela consistait à faire parler des interviewés aussi longtemps que possible, puis, en reportant les mots prononcés dans des cahiers organisés de façon alphabétique, compter ces mots et leur contexte afin d’en tirer des structures et un diagnostic.
C’était long, fastidieux, d’une fiabilité d’autant plus douteuse que notre homme payait ses chargés d’étude avec un lance pierre. Les chargés d’étude provenaient en direct de milieux gauchistes qui vomissaient naturellement l’idée de marketing.
Cette technique s’appelait la lexicométrie : un nom qui résonnait comme de la science, presque de la science fiction !
La première chose que l’on me demanda fut de trouver un moyen informatique de traiter le langage. Je m’acquittai de la tâche en trouvant un informaticien qui vit en notre société un moyen de s’enrichir à bon compte. Et pendant deux ou trois ans, il m’abreuva de piles énormes de listings pleins de mots en colonnes et de chiffres que j’étais presque seul à comprendre. Nous fîmes même forte impression à un congrès d’informatique où l’idée de rapprocher le langage et l’ordinateur évoquait la science fiction.

Puis, un jour je revins d’Angleterre avec un gros clavier en plastique, un Video Genie de 16k. Le machin enregistrait ses données sur des cassettes audio … Mais je m’apreçus qu’il n’était pas très difficile, même avec ce truc, de compter les mots et d’en faire des listes.
Au bout de deux ou trois ans, après avoir acheté un TRS80 beaucoup plus puissant, j’étais parvenu à remplacer avantageusement l’informaticien. Je travaillais avec un ordinateur portable (12 kg), j’avais rempli ma mission.

Comme j’étais mal payé, je quittai le cabinet et fondai le mien.
En 1988, lors la grand messe du marketing international, le congrès de l’ESOMAR, je fis sensation en démontant la lettre de François Mitterrand aux Français. J’y montrais que le mot JE était très prépondérant et entouré d’un riche contexte social, littéraire et historique. En revanche le mot ÉCONOMIE était très éloigné, entouré d’un contexte plutôt défavorable et sans le moindre lien avec le JE. Boum ! Applaudissements ! Les études de marché ne sont pas franchement à gauche.
Nous étions en 1988 et les questions fusaient, chargées de perplexité. On se demandait avec insistance si, un jour, le traitement informatique du langage aurait une véritable utilité …
Le texte présentant l’analyse de la lettre de Mitterrand s’est malheureusement perdu, mais l’article imprimé est reproduit ici, sans retouches.
Plus tard, au fil des projets, j’ai pu renouer avec la lexicométrie en utilisant des logiciels commerciaux tels que Word et Excel, mais ce fut de façon sporadique et rarement à la demande expresse des services marketing des multinationales pour lesquelles j’oeuvrais. En cause, la complexité, le coût et la durée de tels travaux, qui dépassait de loin les ambitions du commerce.
Et puis, je viens de découvrir, dans Science & Vie que la lexicométrie est toujours active, quarante ans après, dans les universités, en suivant visiblement les mêmes principes :

Words and bytes : the uses of linguistics in qualitative studies
By Pascal Fleury, Managing Director, Trilogy, France.
ESOMAR conference Lisbon 1988
Best methodological paper award
SUMMARY
The applications of computer language analysis in studies originated when micro-computing, linguistics and marketing came together. Since the principal element available for studies is language itself, analysts have concentrated upon creating methods and tools which enable them to analyse it.
A word’s meaning depends upon the context of the other words which surround it ; lexicologists have created tools which make the best use of this environment and have applied this to market research. In this way it has been possible to create new computer programmes which bear little resemblance to software available on the market (word-processing, data bases, translating machines), it was only when users began to have easy access to computers that they concentrated upon the full development of language analysis, but by woking alongside them with the aim of obtaining clearer results and responding to the increasing demands of advertisers who want to know, to the exact word, the positioning of their product, the image of their brand or the specificity of their target.
The development of computer language analysis is highly dynamic, and one is often surprised to discover how many people are actually working on it.
WORDS AND THOUGHT
In the early 80s, when linguist first became interested in marketing, they came under fire because it was generally considered that they converted human thoughts into the compilation of lists of words. This criticism was quite understandable if you consider that these same linguists were attacking psychologists, declaring that if something has not been said or written, it had not been thought. Today, this conflict no longer exists : linguists no longer monopolize language any more than psychologists do the mind. Moreover, it has been recognized that an effective classical analysis depends first and foremost on the quality of category definition along with the identifications made by analysts.
But all of this can be greatly improved by the use of language analysis. Intuition, suspicion and supposition give ay to systematic and exhaustive analysis which are both more thorough and more rigorous. Consequently, the analyst can go further while the client obtains more, better structured details. He has more confidence in his decisions since he can base them on indisputable facts : an exhaustive analysis of the corpus of study material, down to the very last detail.
Language and thought are no longer opposed and are integrated into the one incontestable source of study material : what has actually been said.
To realize the influence of language on expressing thoughts, let us imagine the dialogue which could take place between and Eskimo, who has 55 words to designate snow, and a Frenchman, who only has one …
In the same way, let us see what happened when we interviewed mothers and children on the subject of tea-time (« le goûter » – i.e. a snack which is served to children when they return home from school) :

It is quite clear that children are far more expert than their mothers in describing teatime. For example, they described 39 kinds of chocolate. It is also clear that the dialogue of a child with a traditional mother will be easier than with a modern mother. This paradox was a very useful factor when we were working on the communication to be used for a chocolate spread.
THE BEGINNING
At the end of the 70s, market researchers became interested in the work being done on language in universities.
The CNRS (Centre National de Recherche Scientifique) made an analysis of the words used in the leaflets handed out during the riots of May 1968
Robert Escarpit wrote a curious novel called LITTERATRON which dealt with words used to convince and their analysis by computer.
In other sectors, considerable interest was being shown in language analysis by computers :
the compilation of « Trésor de la Langue Française » by computer (one of the most complete dictionaries of the French language)
the compilation of a French dictionary at Saint Cloud research centre using index cards listing all the possible uses of a word
analysis of the Bible by computer at the Maredsous Abbey in Belgium
research by the European Communities and international organisations into translation problems
work by the Universities of Liège and Louvain on lexicology
development by the MIT (Massachusetts Institute of Technology) of extensive work on language structures.
All of this work resulted in :
- tools for the automatic synthesis of language
- programming languages which are user comprehensible (PL 1).
Political speeches were also studied from the language analysis point of view (« 800 words to convince » in 1978) and even ELSEVIER has contributed to the development of lexicological disciplines.
All of these activities revolved around three very different domains of competence :
computer experts who worked above all for companies on accounting or industrial problems
linguists who were oriented exclusively towards universities, literature or politics – but certainly not marketing
marketing experts who, for the most part, had never heard of linguistics, and if they had, it had usually been presented in incomprehensible terms by semiologists.
When I defended my « Doctorat d’Etat » thesis on linguistics and publicity, the jury of the university insisted on pointing out that they had nothing to buy and that I had nothing to sell to them – which summed up the hostility of universities towards marketing. The climate was far from favorable.
However, some companies (mostly pharmaceutical laboratories, mail order companies, and some institutions such as EDF = Electricité de France) began experimenting with research on language for their communication. At that time, the only way to carry out these studies was for somebody to actually sit down and count the words. If you imagine the idea of working on a corpus of 100,000 words to count, regroup and compare, you will understand that it was a long job which could take months, employing armies of students and the strictest of methodologies. We desperately needed computers, that was clear enough – and we knew that they were already being used for creating dictionaries and doing automatic translation.
The clients, mostly pharmaceutical laboratories, were totally convinced by the efficiency of using language analysis. But it was often necessary to abandon this type of study because it was too costly, both in terms of money and time.
FACTORS WHICH CONTRIBUTED TO THE FULL DEVELOPMENT OF LANGUAGE ANALYSIS
Microcomputers
At the beginning of the 80s, an important even occurred with the development of micro-computing and its rapid increase in capacity. Even if it had been possible to create programmes for language analysis on old, traditional computers, the work had to be subcontracted to outside companies.
The process was costly and was problematic with regard to respecting the timing of studies. It was impossible to control the programmes ; data was created in lots and produced miles of computer printouts ; and the slightest incident or need for extra information meant the whole process had to be started all over again.
Micro-computing should have changed all of that, but at the outset, it was used in other areas, for word processing, data bases and translation. These tools were not so very far from our needs, but were not satisfactory.
It was imperative to create, from scratch, ad hoc programmes which would be completely different from the software available on the market. Thanks to micro-computing, it was possible to create these programmes and make them simple and user-friendly. Moreover, the rapid increase in computer capacities has allowed us to evolve from the experimental stage, where we treated words in hundreds, to our present productivity, where words are dealt with in tens of thousands.
Linguists begin working in marketing
A complete reversal of previous tendencies took place and the hostility of universities towards marketing was converted into a sustained interest. Instead of theories which aimed at exposing publicity, we saw the emergence of work which could be used in marketing and publicity. The indirect result of this reconversion was that more and more linguists and semiologists were hired by marketing and advertising agencies.
At the outset, linguists and psychologists were at war with one another, then, gradually, they began to co-operate. This co-operation resulted in the introduction of more and more varied disciplines in marketing such as anthropology, sociology, ethnology, demography, etc. In this way, while becoming multidisciplinary, research could be legitimately oriented towards language study and focus on building up tools to analyse it.
The needs of marketing
Whatever the product – a walkman, a washing powder, a yoghurt, a car or underwear – the supply market largely conforms to the sociocultural tendencies, the motivations and the sensory needs of the consumer.
In spite of the considerable efforts made by advertisers to satisfy consumer expectations and motivations, this has resulted in an apparent lack of product diversity.
More and more frequently today, advertisers ask to know precisely the words which distinguish their products, in the eyes of the consumer, fro that of their competitors. Linguists have been able to give those answers and contribute to marketing just at the time when they were needed.
The following three factors make their contribution possible :
- the use of software on microcomputers or computers which were easily manageable
- the fact that linguists had studied marketing
- the fact that advertisers wanted to know the precise terms used in their marketing communication.
FROM INDEXES TO CONTEXTS
Indexes
People often confuse lexicological analysis with counting the words of a text. Although word counting is necessary, it is only the first stage of the analysis allowing the compilation of a dictionary and the measurement of the text’s readability (i.e. the simplicity or difficulty of the text in terms of comprehension). So lexicological analysis begins with various basic operations :
the introduction of sentence separators which rationalise punctuation
the distinction between lexical vocabulary (i.e. vocabulary which deals with information such as nouns, verbs, adjectives and adverbs) and functional vocabulary (i.e. grammatical and linking words such as pronouns, articles, conjunctions and prepositions).
These operations are mostly done automatically and structurally by the programme, and result in alphabetical indexes and frequency lists. Then analysis tables are printed.

This table shows that in any text the curve, which shows word frequency, is a parabola.
We know, in particular, that in any text, 20% of the vocabulary is made up of very few words (20 to 50), whatever the length of the text. These are the words which contain the essential information for comprehension, and if they were taken away, the reader would be incapable of understanding what the text was about.
These measurements allow us to compare one text with another in terms of readability. For example, doctors who did not prescribe a certain cardiovascular product used a more complex vocabulary in their discourse, confirming their preference for more sophisticated products ; this aspect was soon confirmed in the analysis which followed.
The distribution of words of varying length gives us precise information. For two strictly equivalent cancer-fighting products, word distribution was as follows :

It is clear that product A proposes a more learned image because the length of the words is directly linked to their lack of frequency in comparison with normal usage. (i.e. there are a lot of different long words used). This difference becomes quite clear in the discourse of doctors who consider product. A more technical and scientific, and product B more practical and easier to get acquainted with.
Thanks to these indexes, the comparison of these indexes to the different quota and the tables we have built up, it is possible to determine at which level communication is, or is not, established.
Contexts
Indexes provide measurements but do not allow us to understand a discourse. It is the analysis of contexts which gives us access to comprehension.
With the birth of linguistics, Ferdinand de Saussure demonstrated an essential point : a word does not represent a reality, and cannot in any way be assimilated with the object it designates.
Even onomatopoeias only evoke reality according to conventions. Let us just have a look at the different ways a cock crows in different countries :
- France : Cocorico
- USA : Cockle doodle doo
- Holland : kukeleku
- Germany : Kikiriki
A word is only a series of letters to which the user attributes a meaning. In fact, the only way to understand the signification attributed to a word is to place it in its context.
In « Advertising and Consumer Psychology », Charles Cleveland from Quester gives an interesting example of this :
A lawyer presenting his client’s case to the jury declares :
« I represent the X,Y,Z corporation, and we began marketing that product to the public in 1964 ».
The analysis made of the words « corporation » and « marketing » in their contextual usages gave :

What he actually said to the audience could be translated by :
« I represent a large, unfeeling, cold, uncaring entity that began manipulating the public in 1964 »
It was anything but a good start !
The meaning of a word in any language comes from the words with which it is used. It also comes from the words which can be used at the same place in a discourse (the synonyms proposed by the person speaking or writing). In this way, for every important or frequent word in a discourse, we make the index of its context, i.e. we identify the words which are most frequently used with it. These indexes are produced from the word and its derivatives (masculine, feminine, plural, singular, conjunctions). The contexts are recorded sentence by sentence and at a maximum distance of +8 or -8 words form the key term.
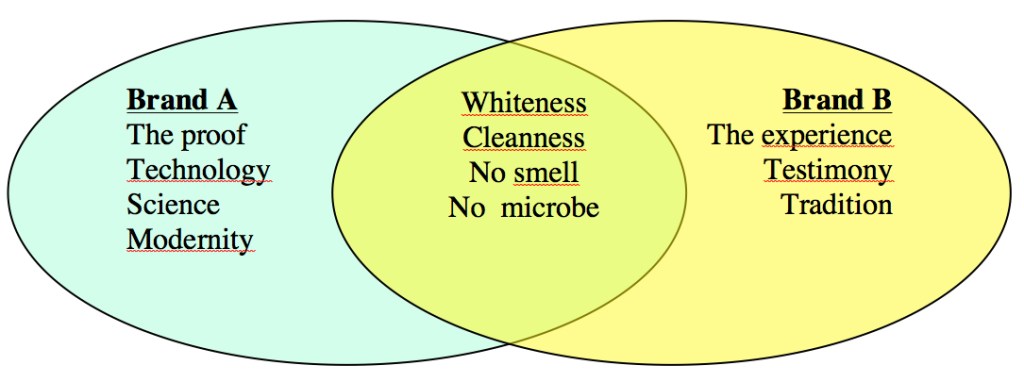
In this way, we can precisely define, for various trademarks, the themes which underlie the image conjured up by the public.
CONSENSUS AND SPECIFICITIES
The listing and the analysis of contexts enables us to isolate the discourse which describes a brand or an concept.
But the real interest of the process is the possibility to compare. For example, to identify the respective positions of competing brands, we extract all of the contexts of each brand and analyse them. We then go on to compare the results.
In this way, for each brand, we obtain :
- the specific vocabulary used in conjunction with a brand or a keyword : This vocabulary is linked to a specific word or a specific brand alone.
- b measurement of correlations between the brands
- the identical vocabulary (for all brands / for certain brands

It is therefore possible to determine :
the image which belongs exclusively to each brand and its context
the consensus of vocabulary used for each brand (by identifying the terms used to describe all of them indiscriminately).
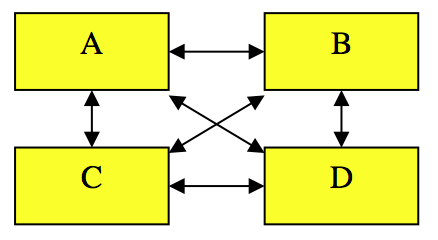
In this way, we can produce the following kinds of diagrams :

DOXA signifies the vocabulary which it is essential to use when indicating to the addressee that the brand belongs to a certain field of the market
Brand D has worked at being original to such an extent that the person referring to it does not identify it as belonging to the same field of the market
Brand E certainly corresponds to the field of market concerned, to such an extent that it has nothing specific : it is a ME-TOO product of brand C.
Using this method, we were recently able to demonstrate that a pharmaceutical product (a painkiller) should in no way identify itself with a certain group of medicines. In this group, one brand was already prevalent to such an extent that the the whole group together never exceeded 10% of the market compared with the leading brand.
This information is reinforced when we directly confront language analysis with concrete market data.
Another application of context comparison consists in interchanging the discourse of different quotas : for example, it is possible to see how the discourse of the users of two leading washing powders, which are apparently equivalent, varies.
The following result was obtained (we are obliged to cover up certain information for professional reasons) :
The correlation is considerable, but for the two brands completely opposite specificities were noted. The computer enabled us to carry out these comparisons quite easily and to give answers to various problems as they were posed. Afterwards, conclusions are rapidly drawn using classical content analysis.
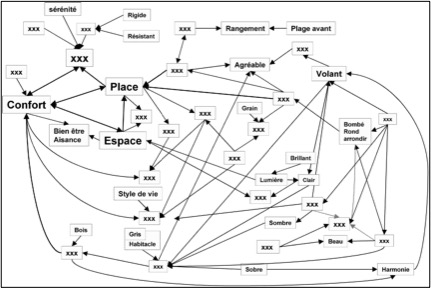
STRUCTURES : THE WORD MAP
A word only has meaning when it is put in the context of the words surrounding it. This basic principle necessarily implies recurrence : each of the words of the context only has a meaning us to identify this recurrence on 20 to 30 levels. This means that with the method of comparison, the most important words of a discourse can be combined into structured which clearly show their correlations as in the following one concerning a motorcar:
These correlations trace zones, blocks of inter-relations, particular derivations, etc. Reading a structure is only possible when the arrows cross one another as little as possible.
When the following relation is found :
It means that these words are used together most frequently and therefore constitute the core of a discourse or text.
Inversely, it was possible to establish that consumers who had been interviewed did not make any link between the following concepts :
- Confort and space
- Aesthetics and modernity
Another structure also revealed that certain themes had very little to do with anything else (even if they occurred frequently).
The themes were important for the interviewees even though they didn’t know what to do with them in practice.
By comparing this structure with one from another quota, we were able to identify that this was precisely where the difference resided : these same terms were completely integrated into the rest of the discourse.
In concrete terms, the advertiser was able to identify the most specific aspects of his target as well as the aspects which should be developed in the promotion of his product in order to attract a wider clientèle.
ALONE IN THIS WORLD
One of the most striking aspects of computer language analysis is that much of the research is carried out in silence, behind the doors of laboratories. It is not infrequent to hear researchers proclaim that they have made interesting discoveries which, however, they refuse to communicate to others.
My own research has been going on for 15 years at a fundamental level ; it is only over the past 8 years that I have applied it to marketing.
One often makes contacts by mere chance : I discovered, fortuitously, that my work was along the same lines as that done by IMW in Cologne who are interested in the evolution of words in language (evolution of the concept of love or pleasure over the past 10 years), and REFLEXIONS in London who uses lexicology in quantitative research.
Recently an English colleague introduced me to an American researcher, Charles Cleveland from Quester, saying that he was doing something unique in the whole world. To our surprise, we soon realized that we were each doing exactly the same thing on each side of the Atlantic. One day I discovered that my neighbours, a Canadian professor, was using his sabbatical year to analyse French literature by computer.
Language analysis has always been encircled by a halo of mystery and fascination. Linguists frequently express their fear of an « absolute language », a language which can manipulate or convince the masses against their will. But language is far too rich and evolves too quickly for us to fear becoming « big brothers ».
On the contrary, throughout the world, analysts have conceived other language analysis tools by computer that go in the same direction, without almost ever communicating among themselves.
From the moment it was possible to treat research material with a computer that had easy access, and with software becoming really performant, the analysts, whatever their training, never hesitated to use this tool.
Language analysis is not a substitute for other analysis done according to other disciplines ; on the contrary, it completes, modulates and deepens it.
Without these other disciplines, language analysis would be an abstract method without any precise aim.
REFERENCES
BENVENISTE E , Problèmes de Linguistique Générale, Paris, NRF, 1966
CHOMSKY & MILLER, L’analyse Formelle des Langues Naturelles, John Wiley and Sons, 1968
CLEVELAND C. (Quester), Semiotics : Determining What The Advertising Message Means To The Audience », Advertising and Consumer Psychology, vol. 3, Olsen J. – Sentis K., 1984
FLEURY P., Le Nouveau Qualitatif, Esomar Congress, Rome, 1984
HÖRMANN H., Introduction à la Psycho-Linguistique, trad. Dubois Charlier, Paris, Larousse Université, 1972
GOETSCHALCKS J. – ROLLING L. Lexicology In The Electronic Age, Commission of The European Communities, Amsterdam – New Yord – Oxford, North Holland Publishing Company, 1981
DE SAUSSURE F., Cours De Linguistique Générale, Paris, Payot, 1951
SANTRY E. – SIDALL J. (Réflexions) Tabloids of Stone, Market Research Society Congress, Brighton, 1988.
Des mots et des octets : l’apport de la linguistique aux études qualitatives
par Pascal Fleury, Directeur, Trilogy, France
CONGRES ESOMAR – LISBONNE – 1988
Grand prix méthodologique
RÉSUMÉ
Les applications dans les études de l’analyse du langage par ordinateur sont nées de la rencontre de la micro-informatique, de la linguistique et du marketing. Le principal matériau d’étude disponible étant avant tout du langage, les analystes ne sont donc attachés à créer des méthodes et des outils permettant de le traiter.
Un mot n’a de signification que grâce à son environnement contextuel, les lexicologues ont crée des outils permettant de rendre compte de la dynamique de cet environnement et de l’appliquer aux recherches marketing. Ainsi, a-t-il été possible de créer des logiciels nouveaux n’ayant que très peu à voir avec les produits informatiques existant sur le marché (traitement de textes, bases de données, machines à traduire). L’analyse du langage n’a connu son vrai développement qu’à partir du moment où l’informatique l’a libéré de sa lourdeur. Elle a trouvé sa légitimité, non pas en cherchant à remplacer d’autres méthodes d’analyse, mais en coopérant avec elles dans le but essentiel d’affiner les résultats et de répondre à la demande de plus en plus pressante des annonceurs de connaître au mot près le positionnement de leur produit, l’image de leur marque, la spécificité de leur cible.
Le développement de l’analyse du langage par ordinateur est très dynamique, et on est souvent surpris de découvrir que son voisin fait exactement la même chose que ce que l’on croyait être seul au monde à réaliser.
LES MOTS ET LA PENSÉE
La principale critique adressée aux linguistes quand ils tentèrent d’aborder le marketing au début des années 80 fut : « vous réduisez la pensée humaine à des listes de mots ». Cette critique pouvait avoir une valeur du fait que les linguistes eux-mêmes récusaient la psychologie et déclaraient « si ce n’est pas dit / écrit, ce n’est pas pensé ». Aujourd’hui, la guerre est finie : les uns n’ont plus le monopole du langage, les autres n’ont plus le monopole de l’esprit. En revanche, un constant très pragmatique a pu être fait : une analyse de contenu classique doit se fier d’abord à la qualité des catégories et des relevés faits par les analystes.
Ces catégories et ces relevés peuvent être très largement améliorés grâce à l’analyse du langage. Les intuitions, les soupçons, les classifications a priori cèdent la place à des relevés systématiques et exhaustifs à la fois plus faciles et plus rigoureux. Il en résulte que l’analyste peut aller plus loin, et que le client obtient plus de détails, mieux structurés. Sa décision en est plus assurée, s’appuyant sur des faits incontestables : une analyse exhaustive du matériel d’étude, poussée dans les moindres détails.
Langage et pensée ne sont plus opposées, ils se traduisent à travers le seul matériel incontestable d’une étude ce qui est dit.
Pour se rendre compte de l’influence du langage pour exprimer la pensée. Imaginons la conversation qui peut exister entre un esquimaux qui dispose de 55 mots pour désigner la neige et un français qui n’en a qu’un.
De la même manière, regardons ce qui s’est produit quand nous avons interrogés des mères et des enfants a propose du goûter.

Il est clair que l’enfant est bien plus expert que sa mère pour exprimer le goûter. Il mentionne par exemple 39 sortes de chocolats …. Il est clair aussi que le dialogue entre l’enfant et la mère traditionnelle sera plus facile qu’avec la mère moderne, paradoxe qui fut bien utile pour concevoir la communication d’un produit au chocolat.
LES DÉBUTS
Dés la fin des années 70, les études marketing prêtèrent attention aux travaux effectués par l’université sur le langage :
le CNRS avait réalisé une analyse des mots employés dans les tracts de Mai 68
Robert Escarpit avait écrit un drôle de roman, le LITTERATRON, qui traitait de l’utilisation des mots pour convaincre et de leur analyse par ordinateur.
Dans d’autres secteurs, le traitement informatique du langage connaissait un essor considérable :
- construction du « Trésor de la Langue Française » (l’un des plus vastes dictionnaires de la langue française) grâce à un traitement informatique
- construction du dictionnaire de la langue française à St-Cloud à partir de fiches répertoriant tous les usages possibles d’un mot
- analyse de la Bible par ordinateur à l’Abbaye de Maredsous en Belgique
- activité des Communautés Européennes et des organismes internationaux sur les problèmes de traduction
- travaux des universités de LIEGE et LOUVAIN sur la lexicologie
- aux Etats-Unis, développement par le MIT (Massachusetts Institute of Technology) d’importants travaux sur la structure du langage.
Ces travaux débouchaient sur
- des outils de synthèse automatique du langage
- des langages de programmation intelligibles par l’utilisateur (PL 1).
Le discours politique fut l’objet d’analyse de langage : « 800 Mots pour Convaincre » en 1978 et même ELSEVIER a contribué au développement des disciplines lexicologiques.
L’ensemble de ces activités fait appel à trois domaines de compétences aussi éloignés que possible les uns des autres :
- les informaticiens : avant tout sollicités par les entreprises pour des problèmes comptables ou industriels
- les linguistes : tournés exclusivement vers l’université, la littérature, la politique et surtout pas vers le marketing
- les hommes de marketing qui, le plus souvent, n’avaient jamais entendu parler de linguistique. Quand ils en avaient entendu parler, c’était par le biais de travaux incompréhensible, proposés par les sémiologues.
En 1978, lorsque je soutins ma thèse de Doctorat d’Etat sur la linguistique et la publicité, le jury de l’université tint à déclarer « qu’il n’avait rien à m’acheter et que je n’avais rien à lui vendre », prouvant en cela était loin d’être favorable.
Pourtant quelques entreprises firent l’expérience des recherches sur le langage des laboratoires pharmaceutiques pour la plupart, mais également des spécialistes de la vente par correspondance et des institutions comme l’EDF (Electricité de France) exploitèrent la lexicologie pour leur communication. A cette époque, il n’existait pas d’autres ressources que de réaliser ces études manuellement et comptant les mots. Si vous imaginez l’idée de compter, regrouper, comparer des corpus de 100 000 mots, vous comprendrez que cela pouvait prendre des mois, nécessitait des armées d’étudiants, des trésors d’ingéniosité et de rigueur.
Nous avions besoin d’ordinateurs de ces ordinateurs dont nous savions qu’ils étaient utilisés pour créer des dictionnaires et faire de la traduction automatique.
Les clients et surtout les laboratoires pharmaceutiques, étaient tout à fait convaincus de l’utilité du traitement du langage.
Mais il fallait souvent renoncer à ce type d’étude parce qu’elles étaient trop couteuses en temps et en argent.
b) Les linguistes entrent en marketing
Ce fut un complet renversement des tendances et l’hostilité déclarée de l’université pour le marketing se convertit en un intérêt soutenu. Aux thèses qui prétendaient « démasquer la publicité » se substituaient de nombreux travaux à l’usage du marketing et la publicité. Le résultat indirect de cette reconversion fut que de plus en plus de linguistes et de sémiologues entrèrent dans les agences de marketing et de publicité.
Au début, les linguistes et les psychologues se firent une guerre ouverte, puis, peu à peu ils coopérèrent. Cette coopération allait de pair avec la multiplication des disciplines telles que l’anthropologie, la sociologie, l’ethnologie, la démographie etc. Ainsi, les études, en demeurant pluridisciplinaires, pouvaient légitimement s’intéresser au langage et construire des outils pour le traiter.
Les nouvelles demandes du marketing
Quel que soit le produit, – un walkman, une lessive, un yaourt, une voiture ou un sous-vêtement, – l’offre proposée s’est très largement conformée aux courants socio-culturels, aux motivations et à la sensorialité des consommateurs. C’est à dire que l’effort considérable fait par les annonceurs pour satisfaire les attentes et les motivations des consommateurs à inexorablement conduit à l’uniformisation apparente des marches.
De plus en plus fréquemment aujourd’hui les annonceurs demandent à connaître par le détail les mots précis qui distinguent leur produit de celui des concurrents chez les consommateurs. C’est à point nomme que les linguistes ont peu venir et apporter leur contribution.
Cette contribution ne pouvait se faire que par la conjonction de 3 facteurs :
- des outils logiciels portés sur micro-ordinateurs ou des ordinateurs facilement accessibles
- des linguistes ayant appris les leçons du marketing
- des annonceurs qui s’intéressaient aux aspects les plus précis de leur communication, à la recherche des termes exacts pour communiquer.
DES INDEX AUX CONTEXTES
a) Les index
On assimile souvent l’analyse lexicologique au décompte des mots d’un texte. Ce décompte aussi nécessaire soit-il, n’est que la première étape de l’analyse, celle qui permet de constituer le dictionnaire de l’étude et de faire les principales mesures sur la lisibilité (la facilité et la difficulté de lecture du texte en termes de compréhension).
Ainsi, l’analyse lexicologique commence par diverses opérations de bases :
- introduire des séparateurs de phrases qui rationalisent la ponctuation
- distinguer entre le vocabulaire lexical (celui qui véhicule l’information, les noms, les verbes, les adjectifs et les adverbes, et le vocabulaire fonctionnel (les mots grammaticaux et de liaison, les articles, les pronoms, les auxiliaires).
Ces opérations sont en grande partie automatisées et structurées par le programme. A l’issue de ces opérations, les index alphabétiques et de fréquence décroissants sont générés. Puis des tableaux d’analyse sont édités (voir page suivante).
Ce tableau montre que dans tout texte la courbe décroissante des fréquences est une parabole.

On sait notamment que dans un texte, 20% du vocabulaire total sont représentés par très peu de mots Il y a quelque chose qui m’a fait clique dans ma tête.
Ce sont ces mots qui transmettent l’essentiel de l’information. Si on les retire, le lecteur est incapable le de quoi parle le texte.
L’ensemble de ces mesures permet de comparer un texte à un autre en termes de lisibilité. Par exemple, les non-prescripteurs d’un diurétique prouvaient par un discours plus complexe leur attraction pour des produits plus sophistiqués, aspect qui se trouvait rapidement confirmé par la suite de l’analyse.
La répartition de la longueur des mots permet de préciser ces informations. Pour deux produits anti-cancéreux strictement équivalents, les répartitions étaient les suivantes :

Il est clair, que produit A propose une image plus savante, du simple fait que la longueur des mots est directement fonction de leur rareté par rapport à l’usage normal de la langue.
Cette différence ressort directement dans le discours des médecins qui considèrent le produit A comme plus technique et scientifique et le produit B comme plus pratique et facile à connaître.
Grâce aux index et à leur comparaison d’un quota à l’autre et aux tables que l’expérience nous a permis de construire, il est possible de déterminer le niveau auquel peut ou ne peut s’établir la communication.
b) Les contextes
Les index mesurent, ils ne permettent pratiquement pas de comprendre le discours. C’est l’analyse des contextes qui permet d’accéder à la compréhension.
Dés les débuts de la linguistique, Ferdinand de Saussure démontra un fait capital : un mot ne représente pas la réalité, il ne peut en rien être assimilé à ce qu’il désigne.
Même les onomatopées n’évoquent la réalité que de manière très conventionnelle. Prenons par exemple le chant du coq dans les différents pays :
- France : Cocorico
- USA : Cokle doodle doo
- PAYS BAS : Kukeleku
- RFA : Kikiriki
Un mot n’est qu’une seule suite de lettres à laquelle un utilisateur attribue une signification. Le seul moyen qui soit à notre disposition pour comprendre la signification qu’il attribue à ce mot est de le restituer dans son environnement.
Charles Cleveland de Quester, dans « Advertising and Consumer Psychology » présente un exemple intéressant de cette re-situation dans le contexte. Un avocat, présentant le cas de son client face à un jury déclara :
« I represent the X,Y,Z, corporation, and we began marketing that product to the public in 1964 ».
L’analyse qui fut faite des contextes d’utilisation des mots « corporation » et « marketing » auprès de ce jury donna :
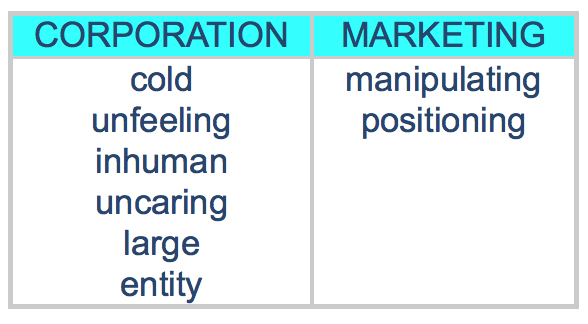
Ce qu’il déclara en fait, à l’audience pouvait être traduit par
« I represent a large, unfeeling, cold, uncaring entity that began manipulating the public in 1964 ».
Cela commençait plutôt mal.
La signification d’un mot provient, à l’intérieur d’une langue donnée, des mots avec lesquels il est utilisé. Elle provient également des mots qui peuvent être utilisés à des places équivalentes dans le discours (les synonymes que lui propose celui qui parle ou écrit). Ainsi, pour chaque mot important et/ou fréquent d’un discours, nous réalisons l’index de ses contextes. C’est-à-dire que nous identifions les mots qui sont utilisés le plus fréquemment avec lui. Ces index sont produits à partir du mot et de ses dérivés (masculin, féminin, pluriel, singulier, conjugaisons). Les contextes sont recensés phrase par phrase et à une distance maximale de – 8 mots et de + 8 mots autour du terme clé. C’est ainsi que l’on peut définir, avec précision, pour plusieurs marques par exemple, l’ensemble des thèmes qui sous-tendent leur image auprès du public.
CONSENSUS ET SPÉCIFICITÉS
Le relevé et l’analyse des contextes permettent d’isoler le discours qui décrit une marque ou un concept.
Mais l’intérêt véritable de la démarche provient avant tout de la comparaison. Par exemple, pour identifier les places respectives de marques concurrentes dans le discours des consommateurs, nous recensons l’ensemble des contextes de chacune des marques, puis nous les analysons. Ensuite, nous comparons l’ensemble des résultats. Nous obtenons ainsi, pour chaque marque :
- le vocabulaire spécifique utilisé en conjonction avec une marque ou un mot clé (comme l’exemple suivant concernant le comportement sur les routes dans plusieurs villes)
C’est le vocabulaire qui est lié à ce mot ou à cette marque et à aucun autre.
- la mesure de ses concordances avec chacune des autres
- le vocabulaire commun : commun à toutes les marques / commun à des couples de marques.
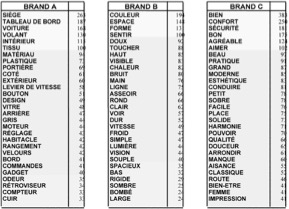
Il est également possible de déterminer, avec précision :
- l’image propre et exclusive de chaque marque en identifiant exactement son étendue
- le consensus absolu des marques en identifiant les termes qui les désignent toutes, sans discrimination.
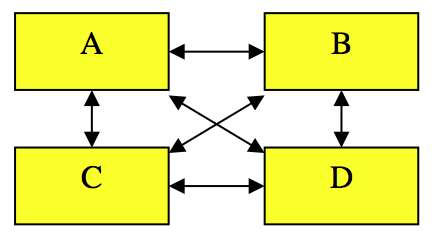
Ainsi se construit des schémas de ce type :

- Nous appelons DOXA les termes qu’il est indispensable d’utiliser pour indiquer à son destinataire que la marque appartient effectivement à un marché donné
- La marque 0 a fait des efforts d’originalité au point que celui qui en pale ne l’identifie pas du tout comme appartenant au marché
- La marque E appartient bien au marché, à tel point qu’elle n’a rien en propre, elle n’est qu’un ME-TOO de la marque C.
Par cette méthode, nous avons pu démontrer, il y a quelques temps, qu’un produit antalgique ne devrait en aucun cas s’apparenter à une classe donnée dans cette classe une marque dévorait tous ses concurrents qui ne dépassaient jamais, à eux tous, 10 % des parts de marché du leader.
Ces informations sont largement enrichies lorsqu’on confronte directement le langage et les informations concrètes du marché.
Un autre usage de la comparaison des contextes consiste à croiser le discours de plusieurs quota : par exemple, l’on peut définir comment se recoupent les discours d’utilisatrices de 2 grandes lessives réputées en apparence équivalentes.
Le résultat fut approximativement celui-ci (pour des raisons professionnelles, nous avons quelque peu modifié les résultats).
Le consensus était considérable, mais les 2 marques construisaient des univers spécifiques absolument opposés. L’ordinateur permet sans peine de réaliser ces comparaisons et de les moduler autant de fois qu’il est nécessaire pour faire apparaître des informations.
Très rapidement ensuite, les conclusions peuvent être tirées grâce à une analyse de contenu classique.
STRUCTURES : LA CARTE DES MOTS
Un mot n’a de signification qu’à travers les contextes qui l’environnent. Ce principe de base implique une récurrence !
Chacun des mots du contexte n’a de sens que par ceux qui l’environnent également. L’ordinateur permet de réaliser cette récurrence sur 26 niveaux. Cela signifie qu’avec la méthode de comparaison, les 26 mots les plus importants du discours peuvent être combinés en structures qui mettent en évidence leurs relations.
Cet ensemble de relations trace des zones, des blocs d’interrelations, des dérivations singulières, etc. La lecture d’une structure n’est possible que lorsque les flèches se croisent le moins possible.
Cela veut dire que ces mots sont le plus souvent ensemble et qu’ils constituent le noyau dur d’un discours ou d’un thème.
A l’inverse on a pu se rendre compte que les médecins parlant d’hypertension reliaient pas du tout les concepts suivants :
– la vie du patient
– le traitement de la maladie
– les produits à sa disposition.

Une autre structure révéla que certains thèmes, même fréquents n’avaient que peu de relation avec le reste du discours. Ces thème passionnaient les interviewés mais ces derniers ne savaient pas quoi en faire dans la pratique.
En comparant cette structure avec celle d’un autre quota, nous avons pu nous rendre compte que c’était là, précisément que résidait la différence, ces même termes étaient complètement intégrés au reste du discours !
De façon parfaitement concrète, l’annonceur pouvait identifier les aspects les plus spécifiques de sa cible et les aspects à développer dans la promotion de son produit pour séduire une clientèle plus large.
« SEUL AU MONDE »
Un des traits les plus saillants de l’analyse du langage par ordinateur est que beaucoup de recherches sont menées en silence, dans le secret des laboratoires. Il n’est pas rare que des chercheurs proclament des découvertes intéressant mais refusent de les communiquer à qui que ce soit.
Mes propres recherches se sont faites, depuis 15 ans au niveau fondamental pour trouver depuis 8 ans des applications marketing.
Le hasard crée parfois les contacts. Ainsi, c’est tout à fait fortuitement que j’ai découvert que mes travaux allaient dans le même sens que ceux d’IMW à Cologne qui s’attachent à l’étude de l’évolution des mots dans la langue (évolution du concept d’amour, de plaisir ces 10 dernières années), ou de REFLEXIONS à Londres qui utilise la lexicologie dans les études quantitatives.
Récemment un confrère anglais me présenta à un chercheur américain. Charles Cleveland de Quester, en me déclarant qu’il faisant quelque chose d’unique au monde. A sa grande surprise, nous constations que nous faisions exactement la même chose, chacun dans notre pays. Je découvris un jour que mon voisin de palier était un professeur canadien qui profitait de son année sabbatique pour analyser la littérature française sur un ordinateur.
L’analyse du langage a toujours été entourée d’un halo de mystère et de fascination. Il n’est pas rare que les linguistes suscitent la craintes du « langage absolu, celui qui manipule et convainc les foules contre leur volonté. Le langage est heureusement bien trop riche et mouvant pour que l’on puisse craindre de devenir des « big brothers ».
En revanche, à travers le monde, des analystes ont conçu des outils d’analyse du langage par ordinateur qui vont dans le même sens, sans presque jamais communiquer entre eux.
Dès qu’il a été possible de saisir et de traiter le matériel d’étude avec un ordinateur d’accès et que les logiciels sont devenus vraiment performants, les analystes, quelle que soit leur formation, se sont emparés de l’instrument.
L’analyse de langage ne remplace pas l’analyse réalisée par d’autres disciplines ; elle l’enrichit, la module et l’approfondit.
Sans ces autres disciplines, ce serait une démarche abstraite et sans but précis.
